-
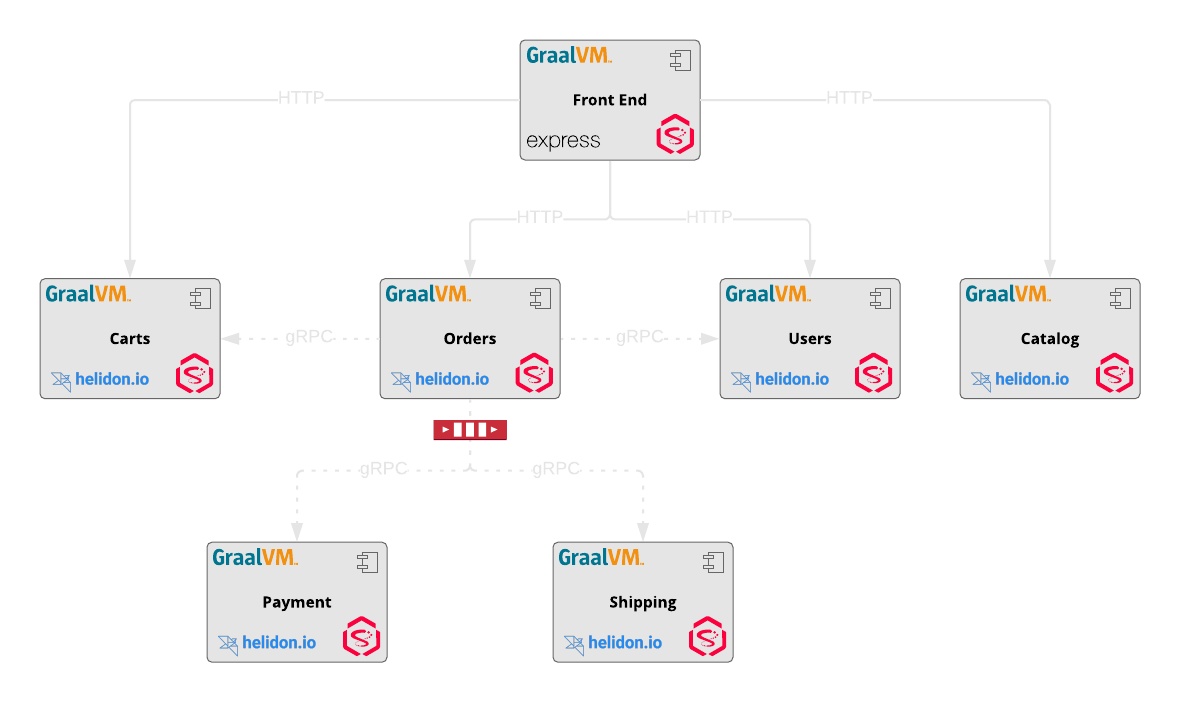
 ARE YOU BUILDINGMICROSERVICES?
ARE YOU BUILDINGMICROSERVICES?
 You've come to the right place
You've come to the right place -
DO YOU NEED TOMONITOR THEM?
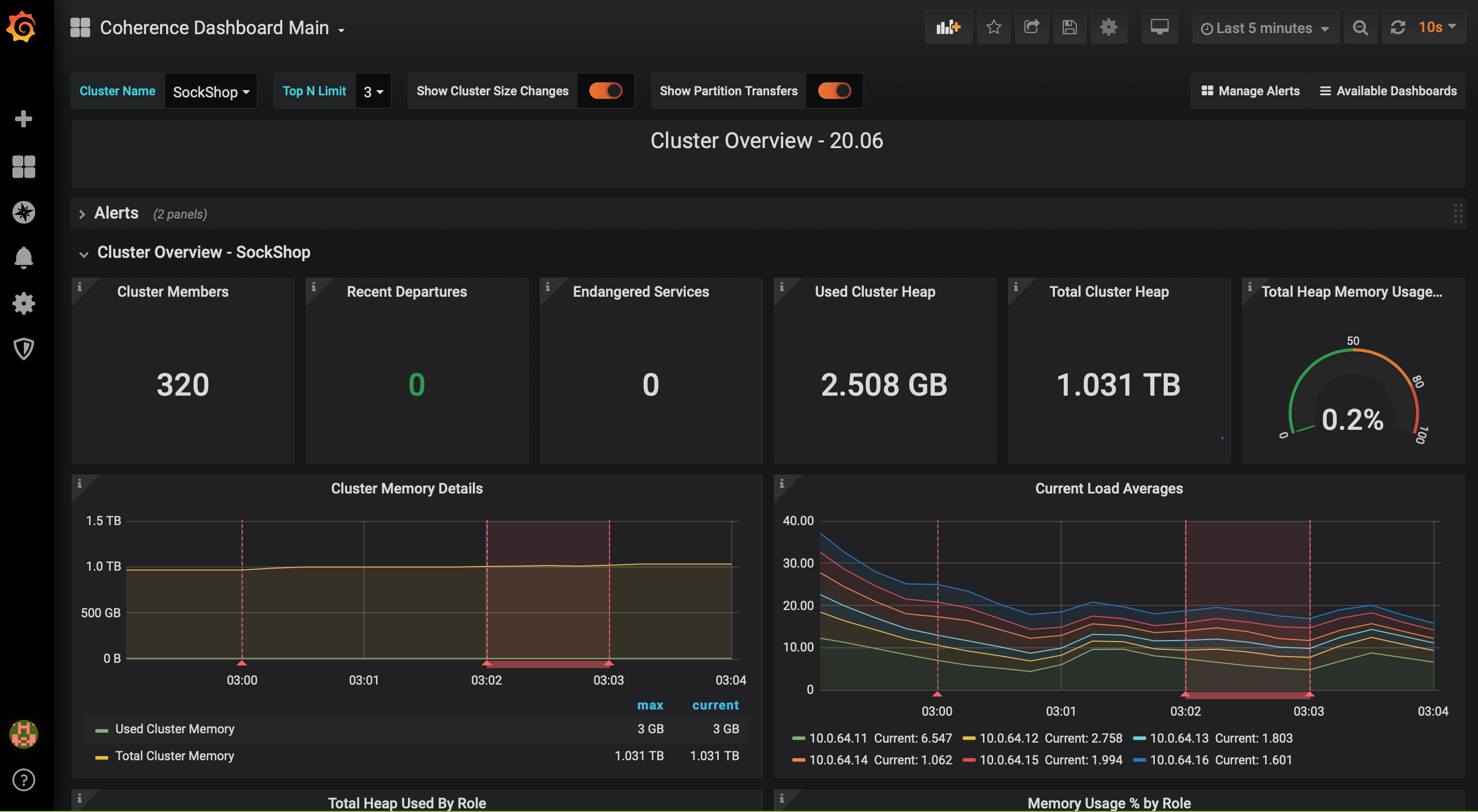
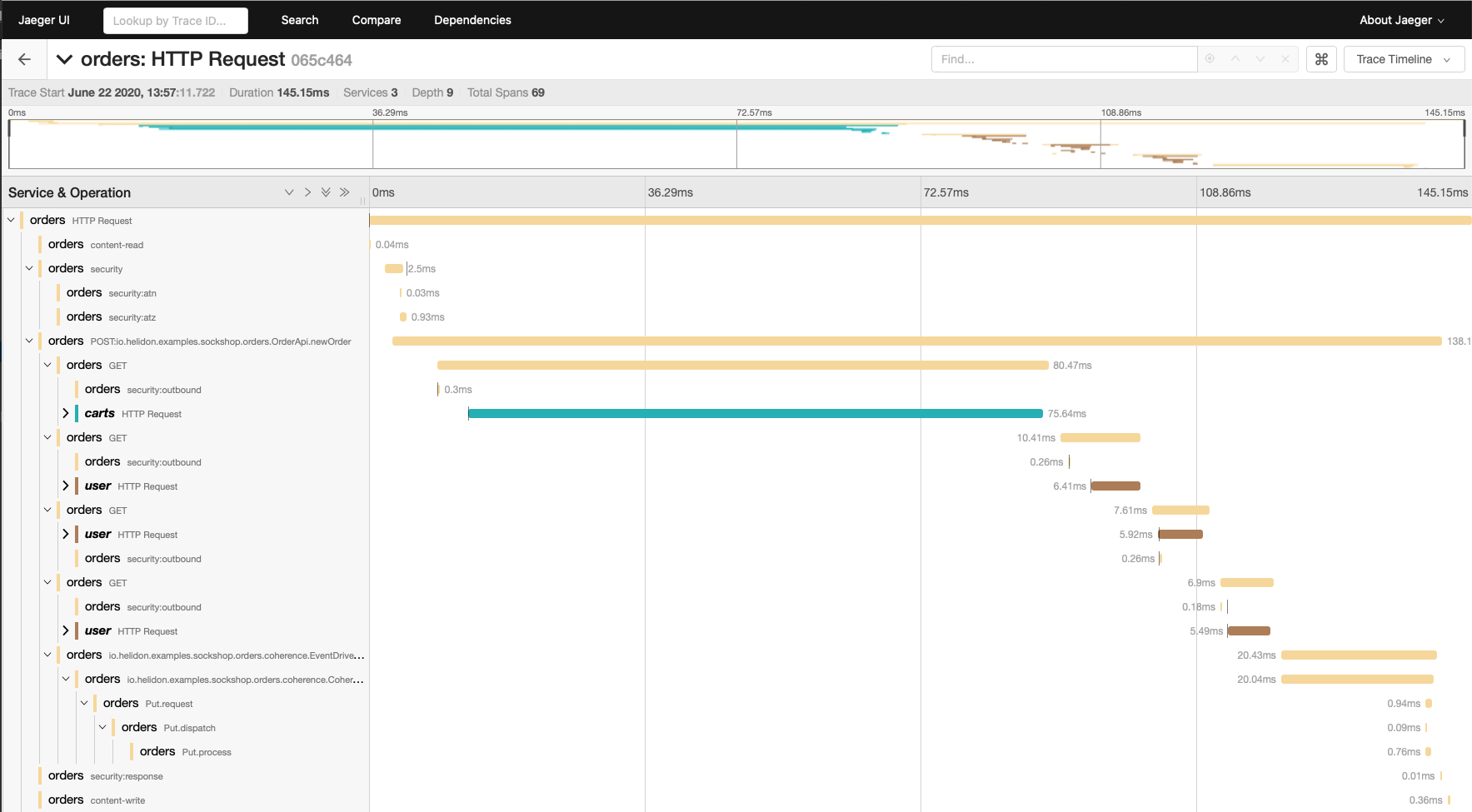 Built-In Support for Metrics and Tracing
Built-In Support for Metrics and Tracing
The best way to build modern stateful scalable cloud native
microservices

Welcome to Coherence Community Edition
Coherence CE (Community Edition) is a free and open source edition of Oracle Coherence, first and market-leading in-memory data grid. Since its initial release in 2001, it has been used by hundreds of customers across many industries to power some of the mission critical systems you use every day. Often immitated, but never duplicated, it is now available for everyone to use free of charge.
Scalable
Coherence clusters can easily scale to hundreds of members (JVMs), all of which can both store and process the data. This allows you to scale both the data storage and the processing capacity by simply adding more members to the cluster, which you can do at any time.
Reliable
Coherence stores each piece of data within multiple members (one primary and one or more backup copies), and doesn't consider any mutating operation complete until the backup(s) are successfully created. This ensures that your data grid can tolerate the failure at any level: from single JVM, to whole data center.
Fast
Coherence is fast. Like, sub-millisecond fast. Each member of the cluster is aware of where each piece of data resides and can access it using a single network call. There are no connections to acquire or release, and no distributed transactions to commit or roll back.
Durable
Coherence can optionally persist data to disk (either local or shared), which prevents data loss even in the case of complete cluster outage. Coherence Grid Edition (commercial) also supports data center replication and application failover.
Cloud Enabled
Coherence comes with its own Kubernetes Operator, which allows you to provision Coherence-based application into any Kubernetes cluster using 5 lines of YAML. It also has built-in support for OpenTracing, Prometheus and Grafana, and comes with a number of custom Grafana dashboards that allow you to monitor cluster of any size in any environment.
Joy to Use
Coherence is just a library that you can embed into your application and start coding against. If you know how to use java.util.Map, you know how to get started with Coherence. From basic gets and puts, to Stream API, it's all there. Once you reach the limits of basic functionality, you can leverage some of the advanced features that will allow you to build better distributed applications.
Clustering and Data Sharding
Coherence requires minimal configuration in order for the members to discover one another and form a cluster. This makes it just as easy to create a cluster of 500 members as it is to create a cluster of 5 members, both on the physical hardware and in virtualized environments.
Once the cluster is formed, Coherence will automatically shard the data across all the members and ensure that each piece of data has a backup copy as well. No cluster member is special, and any member can fail at any given time without significant impact on the cluster as a whole.
In other words, failure is expected and built into the architecture, not an exception.
Scalability and High Avalability
Coherence can be easily scaled out to increase both the storage and the processing capacity, and can be scaled in just as easily to reduce resource usage when the additional capacity is not needed, to the limit of the in-memory data set size.
Whenever you add or remove cluster members, Coherence will automatically rebalance the data by moving some of the partitions to new members or be restoring partitions from backup for the departed members.
Coherence is aware of the network topology and always stores backups as far away as possible from the primary copy. In the common case of a cluster spanning multiple availability domains/zones in the cloud region, this allows you to lose a whole availability domain without any data loss.
Disk-Based Persistence
You also have the option of persisting data to disk, either actively, as the changes happen, or on demand, by taking periodic snapshots of the cluster state. You can use either local or shared disk, but we strongly recommend that you use SSD in either case if you care about peformance. When running inside of Kubernetes, both regular volumes and PVCs are fully supported.
This allows you to quickly restore cluster state from disk in case of catastrophic failure, such as data center power loss, or to speed up whole-cluster upgrades if you can tolerate some downtime. If you can't, you can still use persistence to create backups, and rolling upgrades to perform cluster upgrades while keeping the system fully operational.
Key-Value Data Store
Coherence NamedCache API is an extension of java.util.Map interface, so if you know how to use Java Map, you already know how to use Coherence for basic key-value operations. The difference is that now you have a fault tolerant Map that can be scaled across many cluster members and optionally persisted to disk
Key-based operations in Coherence are very efficient. Every cluster member is aware of the partition/shard distribution across the cluster, and the partition that a given key belongs to is determined using a consistent hashing algorithm. That means that any piece of data is only one direct network call away, regardless of the cluster size.
Unlike some of the competitors, Coherence lets you work with classes and objects like you normally would, and converts them to binary data for network transfer and storage purposes when necessary, using one of the several supported serialization formats.
Parallel Queries
Being able to store and access data based on a key is great, but sometimes you need more than that. Coherence allows you to query on any data attribute present in your data model, and even allows you to define your own query filter if one of the built-in ones doesn't fit the bill. If you defined an index for a given query attribute, it will be used to optimize the query execution and avoid unnecessary deserialization.
Coherence executes queries in parallel, across the whole cluster, by default, allowing you to query across the whole data set at once without worrying about its physical distribution. However, it also allows you to execute a targeted query against a single cluster member in situations when you know that all possible results will be collocated based on data affinity configuration. This allows you to optimize queries even further, by limiting the amount of data that needs to be processed.
Efficient Aggregation
Sometimes you don't need the actual data objects that are stored within the data grid, but the derived, calculated result based on them. This is where Coherence aggragation features come in handy.
Coherence aggregators are similar to Java Collectors -- they accumulate individual data objects into a partial result in parallel, across all cluster members, and then combine partial results from all the members into a final result that is ultimately returned to the caller.
Aggregations can be executed against the whole data set, or they can be limited to a subset of the data using a query or a key set. They also tend to scale linearly, so you can typically improve aggregation performance by simply spreading the data (and the processing load) across more cluster members.
In-Place Processing
If there is one defining feature that makes Coherence stand out from many competing technologies, and allows you to write efficient distributed applications, this is it.
The problem with many applications that both hurts their performance and prevents them from scaling is that they simply move too much data over the network and require complicated distributed concurrency control. Read-modify-write is probably the most common data access pattern in vast majority of applications, even though it is very inefficient way of performing data modification.
Coherence addresses this problem by allowing you to send the data modification code into the grid and execute it where the data is, against one or more entries. This can not only significantly impact how much data needs to be moved over the wire, but it also takes care of cluster-wide concurrency control — each entry processor has the exclusive access to the entry it is processing for the duration of its execution.
Think of it as stored procedures, but using Java lambdas and rich server-side domain models.
Sophisticated Event Model
Coherence allows you to react to almost any event that happens within the cluster: members joining or leaving, services starting or shutting down, data partitions being transferred or restored from disk — you name it, it is probably there.
Of course, you can also observe data modification events, both on the server-side and using any of the supported clients. Whether it's entry inserts, updates and removals, or entry processor executions, it's all observable (and in many cases, vetoable).
Coherence events and interceptors also allow you to leverage Coherence data grid as the central integration hub for multiple back end systems, and provide what appears to be a single unified data store for your front end applications.
And many more...
Doesn't matter if you are a begginer or an advanced developer. Coherence is easy to use, distributed to its core, and has a number of features that will make development of modern cloud native applications a breeze.
Quick Start
Did we convince you to give Coherence a try?
The following sections will walk you through the implementation of a simple To Do List application using Coherence and Helidon, show you how to package it into a Docker image, run it, and prove that it works.
We could've done a simpler, "Hello World"-style app, but where is the fun in that?
Create Maven Project
The pom.xml file is a good starting point for Helidon microservices
that use Coherence as a data store.
Few things are worth pointing out:
-
The parent POM is set to
io.helidon.applications:helidon-mpand we add Helidon MicroProfile bundle and JSON Binding support as dependencies. This ensures that all necessary Helidon dependencies are imported correctly. - We add Coherence CDI Server as a dependency, which ensures that Coherence server is started within Helidon application via CDI extension.
- We add Coherence MicroProfile Config as a dependency, which allows us to configure Coherence using Helidon MP Configuration and changes Coherence logging defaults to align Coherence log output with Helidon logging format.
- We configure Jandex plugin to index any CDI beans we may have, in order to speed up application startup.
-
We configure Jib plugin within a
dockerprofile, which allows us to create Docker image for our service within Maven build, without the need for a separateDockerfile.
Implement Data Model
The Task class on the right represents data model for our to-do
items that is used both within REST API (as a way to marshal JSON requests and
responses) and as a storage data model class in Coherence. It is a very simple,
serializable POJO.
Coherence provides more efficient serialization mechanisms as well, but in this example we are using plain Java serialization for simplicity.
Implement REST API
The REST API is implemented as a JAX-RS resource that will be automatically discovered and deployed by Helidon.
Coherence NamedMap instance is injected as a dependency by CDI,
and is used to implement data access logic in the various resource methods.
Some of the resource methods, such as createTask and
deleteTask are fairly simple and perform familiar Map.put
and Map.remove operations against Coherence NamedMap.
The remaining two methods are a bit more interesting and demonstrate some of
the additional features of NamedMap. The getTasks
method shows usage of Coherence Query API, and calls NamedMap.values
to retrieve filtered, sorted set of results.
The updateTask method on the other hand shows an example of
entry processor execution against a single entry by sending a lambda to a
storage member that owns the task with a given identifier, and updating
the task in-place.
Enable CDI
Our service is a CDI Bean Archive, so we need to make sure it is treated
that way by adding beans.xml file to the resources/META-INF
directory.
Configure Logging
Both Coherence and Helidon are configured to use Java Logging, so we need
to provide necessary Java Logging configuration by adding logging.properties
file on the right to the resources directory.
Build the Service
With all the pieces in place, we are now ready to compile the service and create a Docker image for it.
mvn clean install
mvn package -P docker
Run the Service
Once the Docker image is created, you can run the service locally.
docker run -m 200MB -p 7001:7001 coherence/quickstart
Test the Service
Now that the service is up and running, you can make HTTP request
to the API endpoints using HTTP client of your choice. We strongly
recommend Postman
but curl will do.
curl -i -X POST -H "Content-Type: application/json" -d '{"description": "Learn Coherence"}' http://localhost:7001/tasks
(out)HTTP/1.1 204 No Content
(out)Date: Tue, 23 Jun 2020 10:40:57 GMT
(out)connection: keep-alive
(out)
curl -X GET -H "Accept: application/json" http://localhost:7001/tasks
(out)[{"completed":false,"description":"Learn Coherence","id":"155512ed-bf79-4515-a92a-734f65e721d0"}]
(out)
curl -X PUT -H "Content-Type: application/json" -d '{"completed": true}' http://localhost:7001/tasks/155512ed-bf79-4515-a92a-734f65e721d0
(out){"completed":true,"description":"Learn Coherence","id":"155512ed-bf79-4515-a92a-734f65e721d0"}
(out)
curl -i -X DELETE http://localhost:7001/tasks/155512ed-bf79-4515-a92a-734f65e721d0
(out)HTTP/1.1 204 No Content
(out)Date: Tue, 23 Jun 2020 10:50:05 GMT
(out)connection: keep-alive
Congratulations!
You've just implemented your first stateful service using Coherence and Helidon
What are our users saying?
Stateless systems are extremely data hungry, and state management (at scale) is one of the biggest
challenges we've faced. At our scale, no traditional data layer would've worked.
Coherence allows us to manage 9 terabytes of data in memory, in a format easily consumable by our services. This
enables us to handle 1.3 billion calls, and produce 300 million events per day, across 5,600 microservices.